
 值得买
值得买
华擎推出的AI QuickSet软件套件包含Stable Diffusion WebUI并支持透过Microsoft Olive加速算图效能,根据实测可以带来10倍效能表现。
安装与模型优化
先前AMD在官方博客张贴了在Stable Diffusion WebUI DirectML分枝版本的使用教学,可以透过Microsoft Olive工具将原本PyTorch格式的模型转换为ONNX格式,并在运算时使用DirectML API,达到接近10倍的性能表现。
不过在跟随教学操作的过程中遇到一些技术问题,目前尚无法排除,导致无法套用效能优化,好在华擎推出的AI QuickSet软件套件,大幅简化整体安装流程,用户只需在精灵的协助下安装程序,不需额外的设定就可以享受效能AI大幅提升的优势。
不过需要注意的是,电脑中需要有华擎 AMD Radeon RX 7000系列显卡才能安装AI QuickSet。 华擎官方也表示目前AI QuickSet程序将会持续发展,并在未来加入更多实用的AI应用程序,为用户带来更多元便捷的AI功能。
AI QuickSet下载位置:

▲ 根据AMD官方提供的数据,使用Stable Diffusion WebUI DirectML分枝版本搭配转换为ONNX格式的模型,可以带来近10倍的算图效能表现。

▲ 华擎推出的AI QuickSet软件套件可以简化Stable Diffusion WebUI DirectML分支版本的安装。

▲ 这次测试使用的硬件为华擎Radeon RX 7800XT Steel Legend显卡。

▲ 可以在华擎官方网站下载AI QuickSet。
▲ 安装过程与一般Windows应用程序相同。
▲ 以1.1.13版为例,安装完成后,桌面会出现3个快捷图标。
出图性能提升10倍
如果想要使用优化性能的AI算图环境的话,可以执行「Launch Stable Diffusion WebUI ONNX」捷径。 不过需要注意的是,目前DirectML版本仅支持使用Stable Diffusion 1.5基础模型,网页界面中的Olive模型转换工具无法用于转换其他Checkpoint模型(程序以Hard coding方式指定模型档案),且尚不支持套LoRA,功能限制比较多。 若想要使用其他模型则可以执行「Launch Stable Diffusion WebUI」捷径。
开启DirectML版本的Stable Diffusion WebUI界面后,需在左上角的Stable Diffusion checkpoint下拉式选单选择「stable-diffusion-v1-5-olive [Optimized]」,其余操作则与一般版本相同。
使用华擎 Radeon RX 7800XT Steel Legend进行测试,过程将Batch size分别设定为1、4,Batch count则固定为1,执行2轮测试确定测试结果无极端值后,取平均作为测试成绩。
从结果可以看到,AMD显卡在优化之后,效能有接近在768 x 768分辨率下,Batch size为1时每次计算1张图片,DirectML版本的效能为一般版本的约4.64倍。 若将Batch size设定为4,每次同时计算4张图片,DirectML版本的速度不会受到太大的影响,但一般版本的速度却会严重下降,导致性能落差达到45.29倍。
▲ 第一次执行的时候,程序会自动安装需要的档案并转换模型,需要等待比较久的时间。
▲ 第二次执行之后开启的速度就会恢复正常。
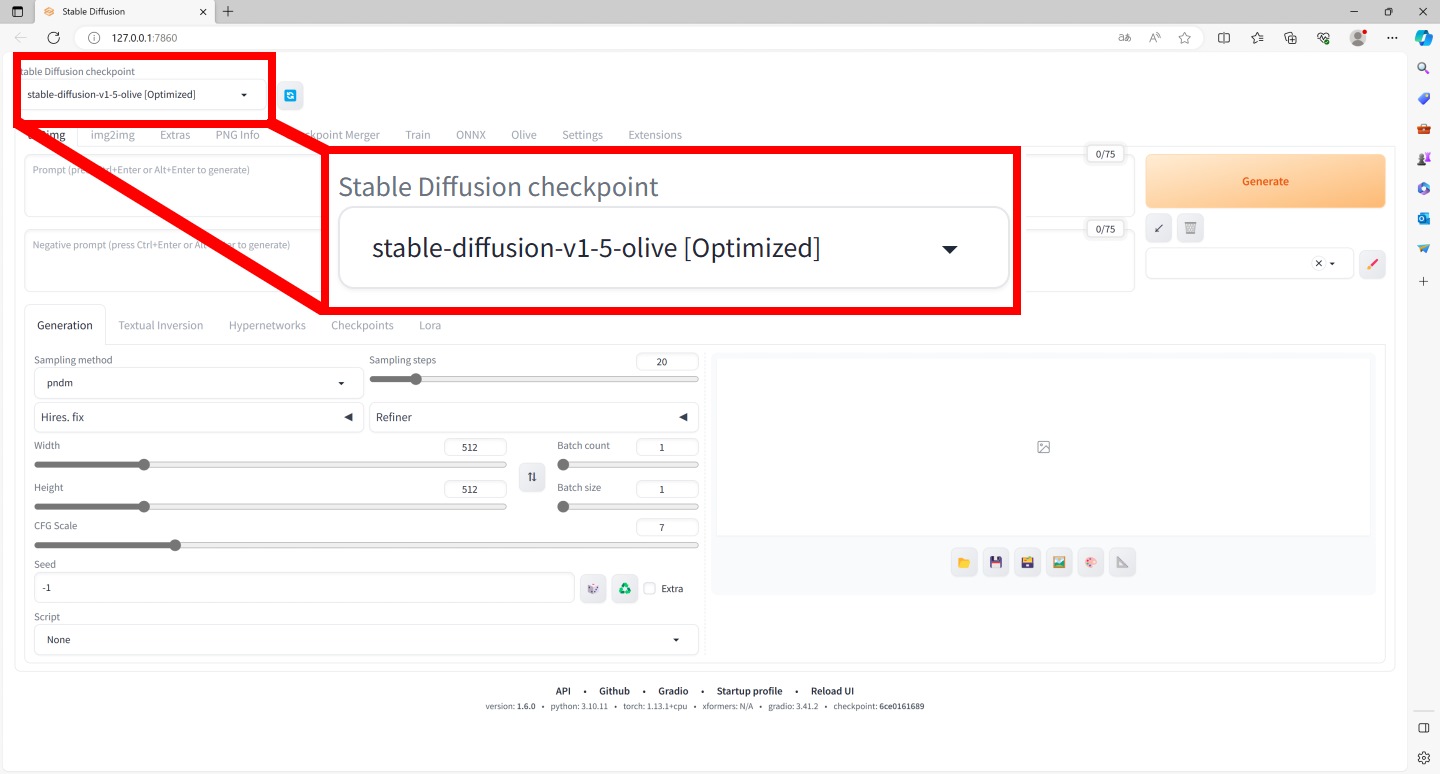
▲ 执行时需在左上角的Stable Diffusion checkpoint下拉式菜单选择「stable-diffusion-v1-5-olive [Optimized]」,以套用最佳化模型。
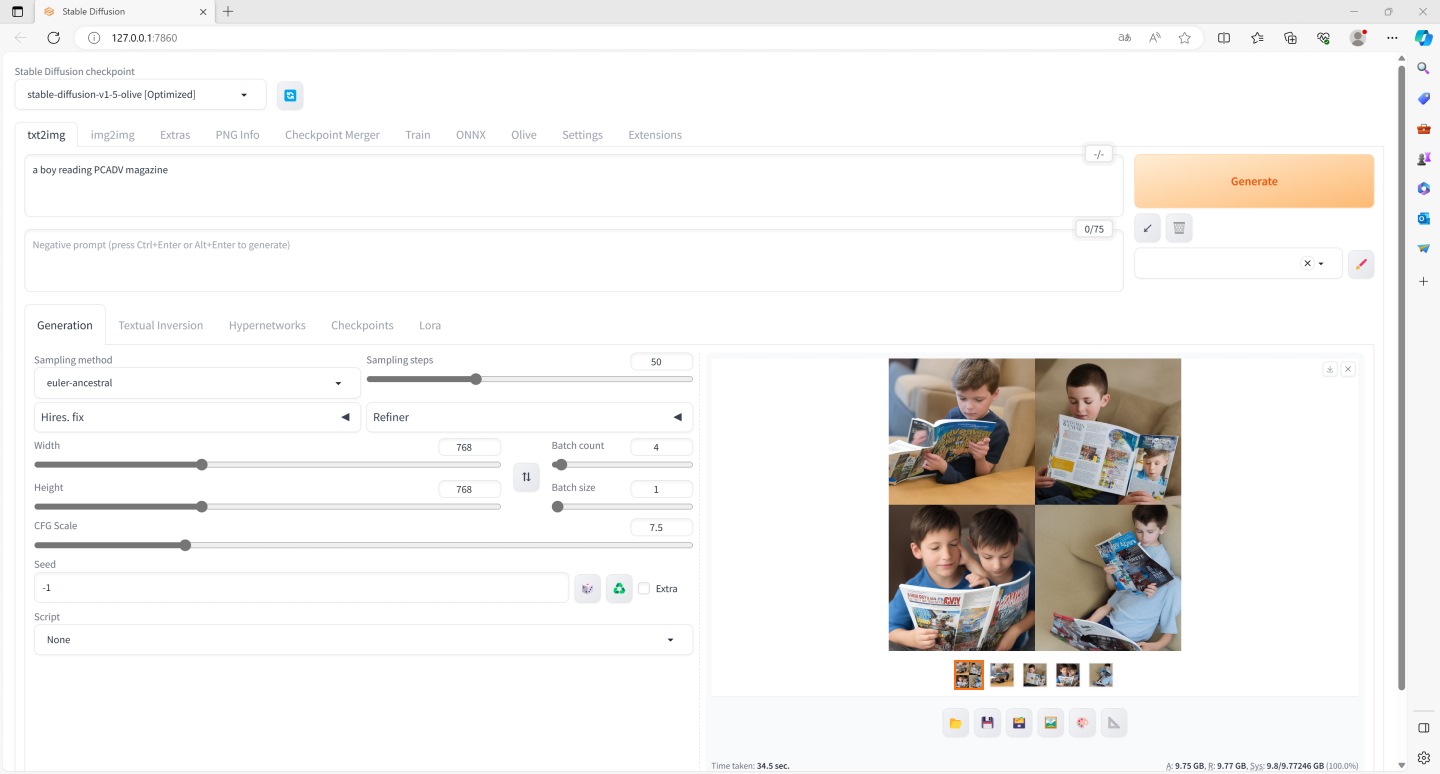
▲ DirectML版本的参数设定与执行结果。
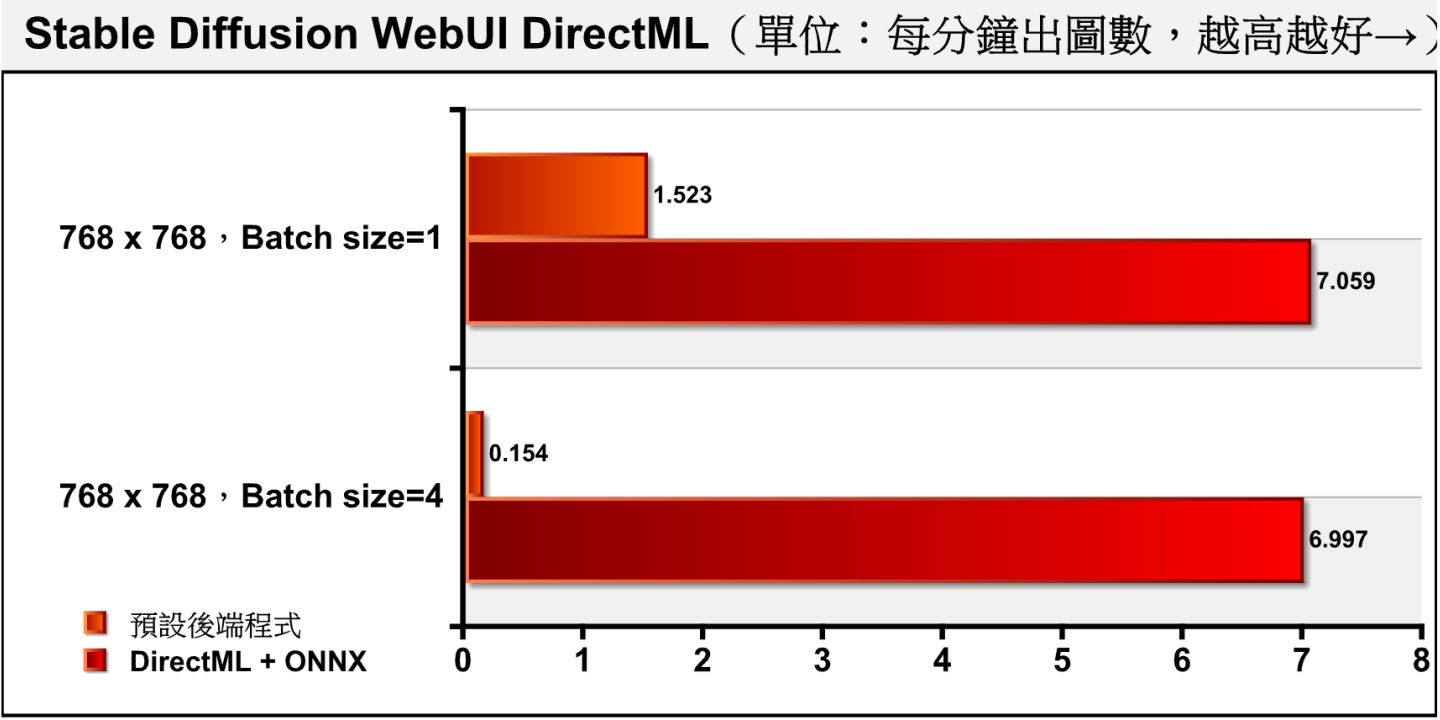
▲ 在Batch size设定为1时,DirectML版本的效能为一般版本的约4.64倍。
AMD的Olive工具可以带来有效的效能提升,但与NVIDIA提供的TensorRT最佳化工具相比方便性与实用度都稍嫌不足,同样有待日后更新改善。
该组件在其它品牌上的AMD 7000系显卡未测试过,不清楚是否可以使用,不过网页上说是只能华擎的7000系显卡才可以使用。
未经允许不得转载:值得买 » 华擎-AI-QuickSet能让AMD-7000系显卡提升10倍SD-AI绘画性能








